见闻:
旦又赢 - 摘自上海交大微信公众号《二月十三》:
上海交大的system方向研究者在本次论坛非常活跃。
在system领域交大拥有一个名为IPADS的魔王研究组,领头人是陈海波教授。可能有部分同学在8月份去南昌的时候听过他们讲的HeDB工作,故事讲得非常好。本次会议IPADS研究组参与的论文报告都做的非常精彩,能在短短15分钟由浅入深得把外行讲得有兴趣去读他们的文章
(并不是我对他们有滤镜,确实是有东西的,包括PPT的排布方式,他们在顶会论文中的图都画得非常好)。
想给拨冗来看这则帖子的读者一个简单印象,比如这种:
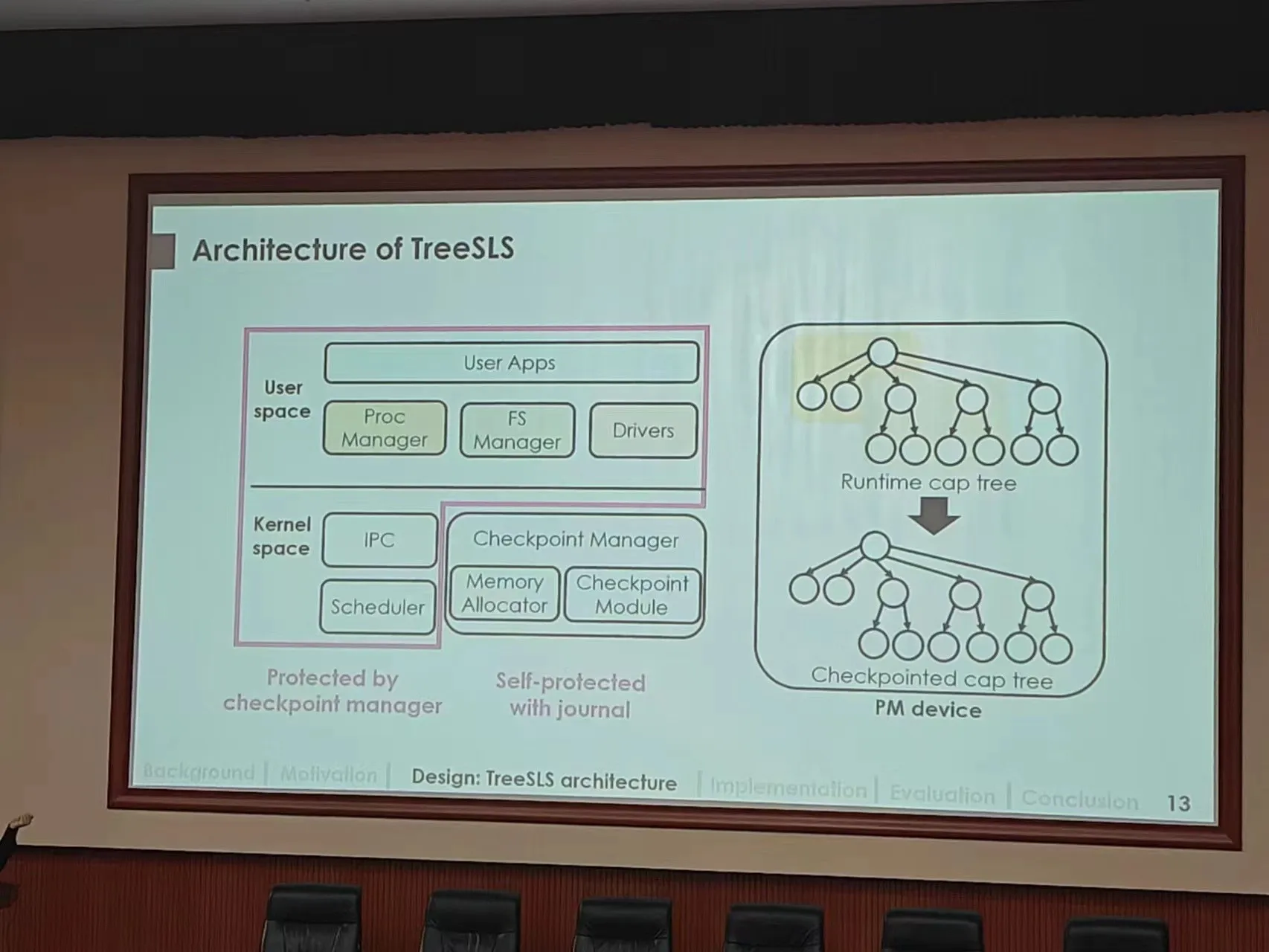
这是今年SOSP的best paper,虽然是系统方向的顶会,阅读真正的工作会有相当的难度,但如果你上过操作系统的课,你应该马上能看出几个点:
- 树形多模块 -> 微内核Chcore
- 崩溃日志管理 -> 树型架构,利用checkpoint打快照进行NVM内存错误缓解
这张图画得非常精简,但是你几乎能推断出这篇文章干什么了,文章标题也很直接:TreeSLS
除了IPADS,上交其余研究组的同学在提问环节也表现地相当活跃,提出的问题也很有意思。
散会后i/e二象性的我强迫自己去找IPADS的李明煜(HeDB的作者)聊聊,向他询问怎样才能训练包括讲故事、提问、presentation、在完全不懂某个研究领域还能提出不错的问题、以及能够快速掌握一个新的研究领域的能力。他提到本质上这些都是方法论上的能力,而不是掌握了某些细节知识点后才能培养出来的,大体培养周期可能要在半年左右,需要积极地参与研讨报告,尝试不断被challenge和challenge的过程才能找到些感觉。
“这个需要有人带, 这一系列方法论很要紧,最好早点培养出来。”
e人魅力时刻(×)
鸡架的意义
本次论坛看到了一些基于同组人士过往工作鸡架,不断精进自身工作的例子。
IPADS的Chcore,如果你买了银杏书,可能已经学习过IPADS基于xv6实验框架和ARM架构制作的微内核Chcore了,这份工作实际上发表在ATC20上,是助理研究员古金宇老师在其读博时的工作,基于这个工作,其还在Usenix相关A会上发表了诸如进程间通信加速等诸多工作,本次汇报中的TreeSLS恰是基于Chcore做的。
(虽然cue人似乎不太礼貌,以前读书时只是听说过大佬)和鄙人同级,来自计算所先进计算机研究中心的王嵩岳同学基于南湖架构设计的xAMU,设计异步内存单元(没错这边的A其实是异步),并扩展ISA,添加异步内存访问相关指令以加速Out-Of-Order情境下时内存访问速度。报告逻辑清晰,非常精彩。
特邀报告中包所提到,他对体系结构四大顶会中有三四篇文章基于香山来做这件事感到非常欣慰。
同在特邀报告之中,北京大学的刘譞哲老师在讲大模型时,展示了近些年自己组针对系统软件全栈所做的工作,并展望了一下大模型对于相关软件栈可能提供的机遇。

似是故人来:
见到了一些熟人,要到了IPADS的李明煜博士的微信自不必说,还有一些熟人面孔。
南大网红老师当了OS session的主持人,经典墨绿战衣,非常感谢其公开资料对鄙人研究生自学工作的方法论指导:
有本科同班同学老哥想通过我找蒋老师要签名,我社恐犯了(我bocchi了)(主要还是不知道聊什么研究方向之类的),不好意思,我没去要。

和前来做特邀报告的武成岗老师聊了很久(因为我方向和他相近辣),直到茶歇结束,聊完后俺说了一句“以前上过您的课”,老师秒懂,他很开心。

BTW:向武老师请教他们组近期发表在安全领域四大顶会的SEIMI,CETIS等工作是怎么想到的,这一类工作的工作思路大致是,挖掘现有硬件机制的潜力,让他们做“与设计时的目的”“不太相同”的事情,然后做一些安全与隔离的事情。
武老师说:我们组里的学生和青年学者们首先确实对ARM和x86相关特殊硬件机制有比较全面的了解,(笔者注:所以确实RTFM很重要啊喂)这才能整活。此外ARM本身设计时有一个特性,即明明有很多功能他们还没有很明确怎么一起用上,但先把它设计出来了,这就给了我们一些有意思的操作空间。当然,最关键的是,从SEIMI参考Dune(OSDI '12,来自斯坦福大学的工作)做出来后,学生们觉得整活很有意思,很好玩,毕竟这些硬件机制它们设计出来不是为了解决论文中所说的那些目的,所以就继续做下去了。
笔者注:这样带来的好处也比较明显,正是因为出其不意,论文中稿后往往有很高的排名,像CETIS是最佳论文提名奖
第一天会议的时候,老胡也在,不过他只是在非常认真地听,很多专家向他恭喜3A6000的事情。
学术猪八戒:
由于忙着做其他事,茶歇时我一杯咖啡都没炫到(叹),并不是咖啡之类的东西不够,单纯是我自己作的。
来听讲的大伙其实对茶歇有着巨大的热情,让我想起高中抢饭排队的盛况。
看到很多同行吃得非常开心,感谢兰州大学的后勤支持。
大模型:
学术界和产业界对于大模型的未来都带着莫大的热情,在lzu_16_morning.pdf中,你可能已经看到刘譞哲老师引申了多少个点了(笑),我觉得他的语文一定很好,6分题可能有能力答6个点,不过这些点确实挺中肯的。
产业界今年邀请了来自华为,达坦科技(公司不大但是很有野心,在网上开展很多很多自学社区,想自学的同学可以多关注),蚂蚁和OPPO的大佬们一起聊聊大模型,以及当前产业界的一些痛点问题。

在lzu_16_afternoon.pdf中,整理了他们所提到的一些潜在方向。
重量级还有来自北大的博士苗旭鹏,他是数据库领域的专家,现在在CMU做博后,居然已经中了一篇大模型系统方向的工作!简直是超人。
论文细节不再赘述,不过其中他有个方法论很好:
我们的需求是A,B,C,D,为了让这些需求能够得到满足,我们针对他们设计了A,B,C,D四个模块。
这说明他的需求构造得非常好,四个需求和模块并没有重合的部分,这样帮助他依据需求快速设计模块,并把他们有机地结合起来。他的讲演思路有点过于清晰了。