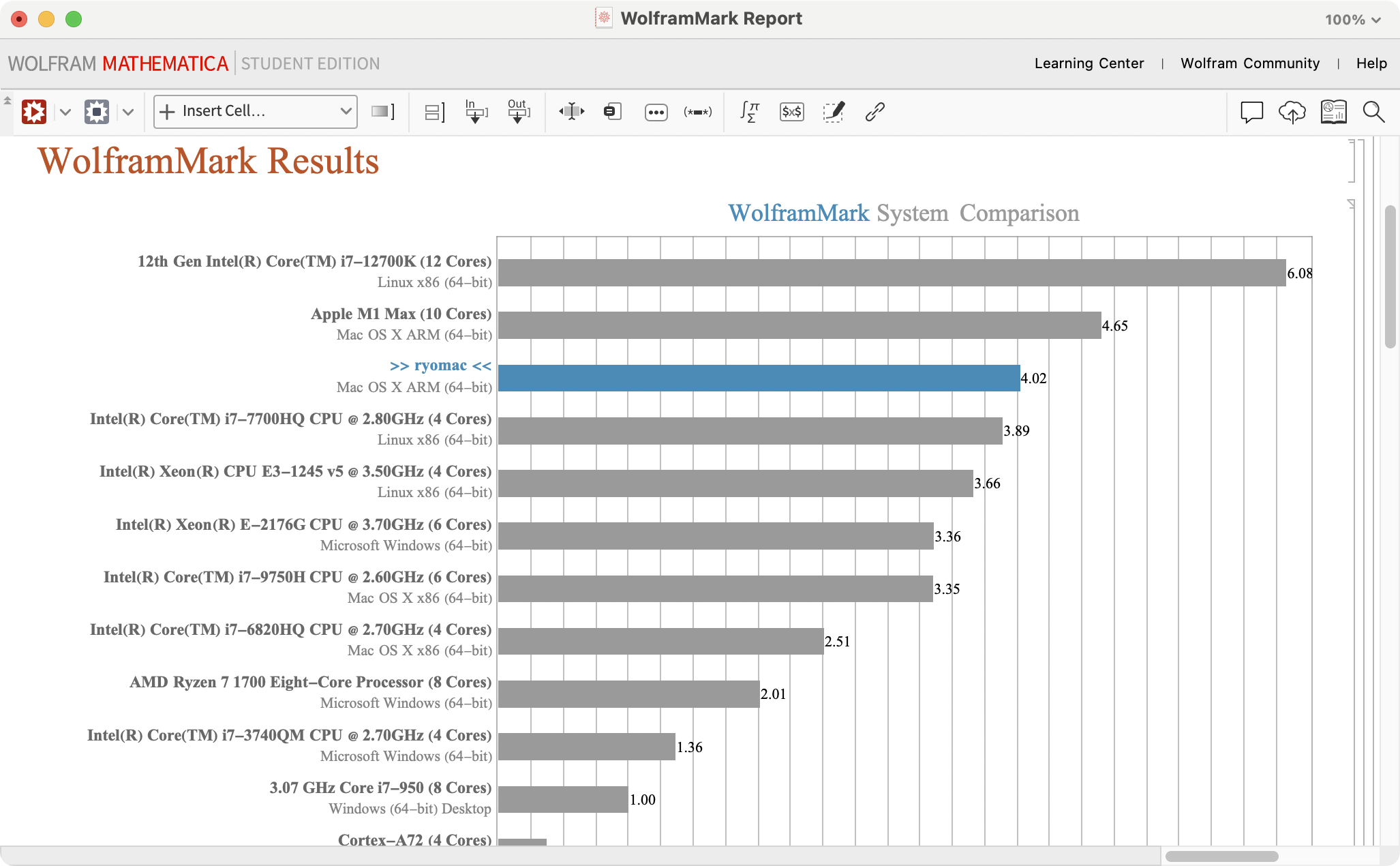
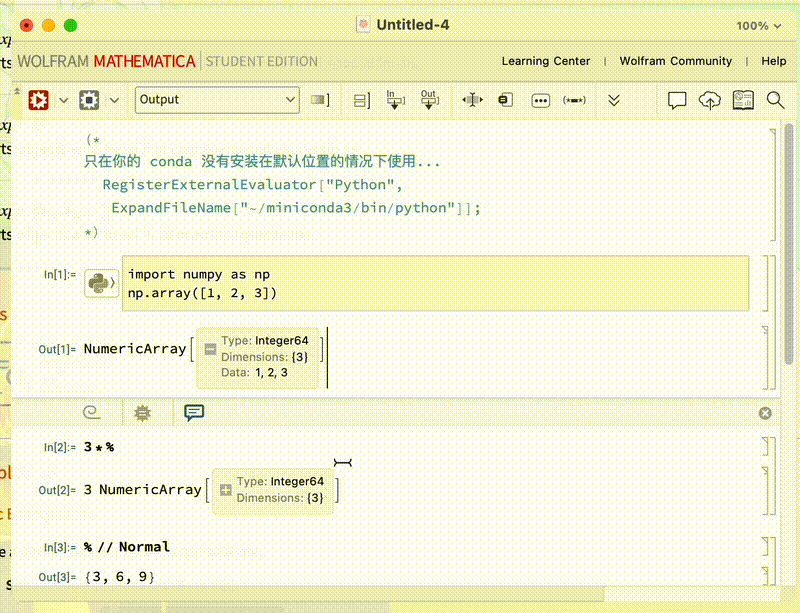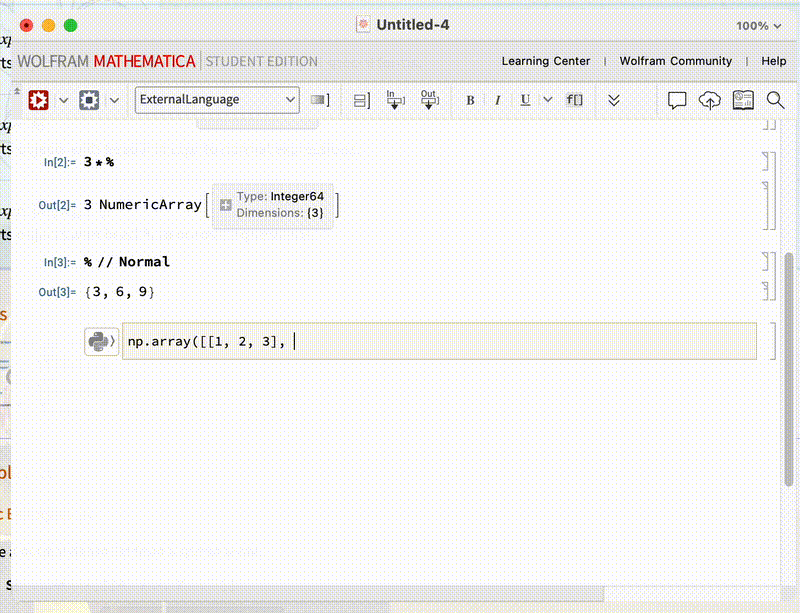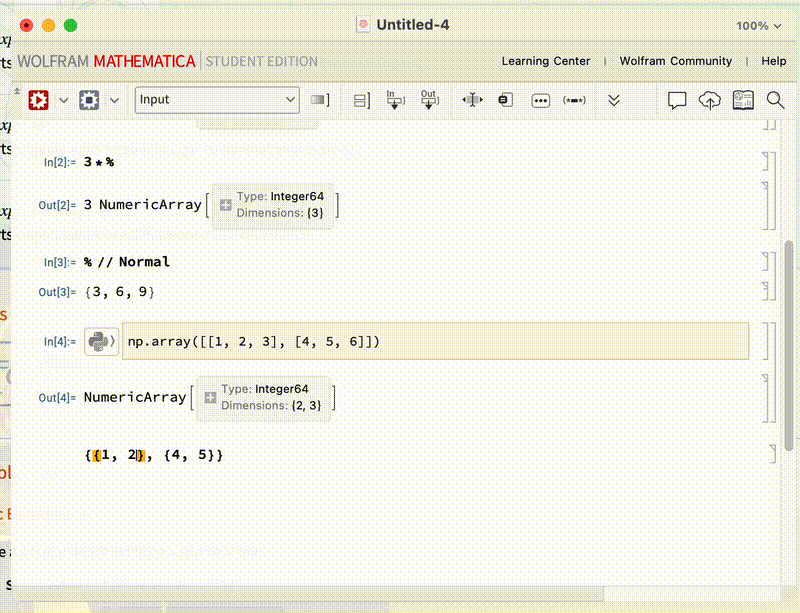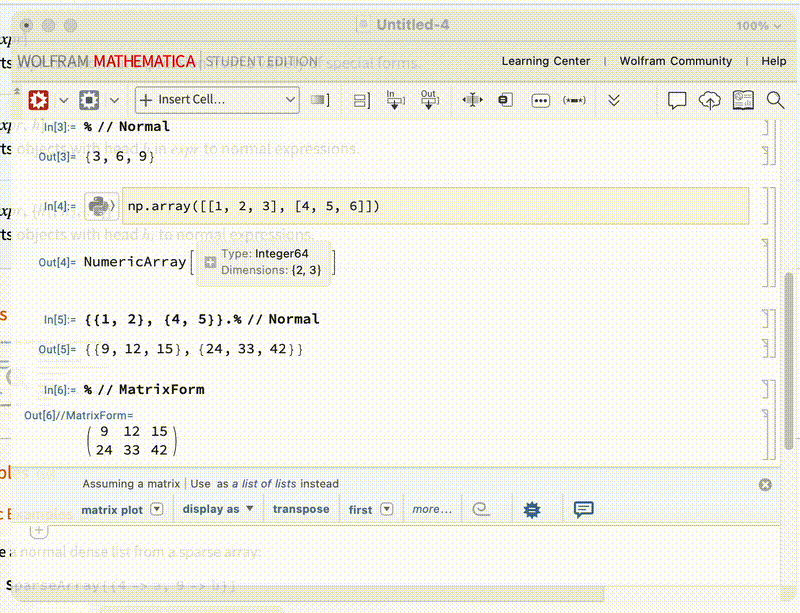
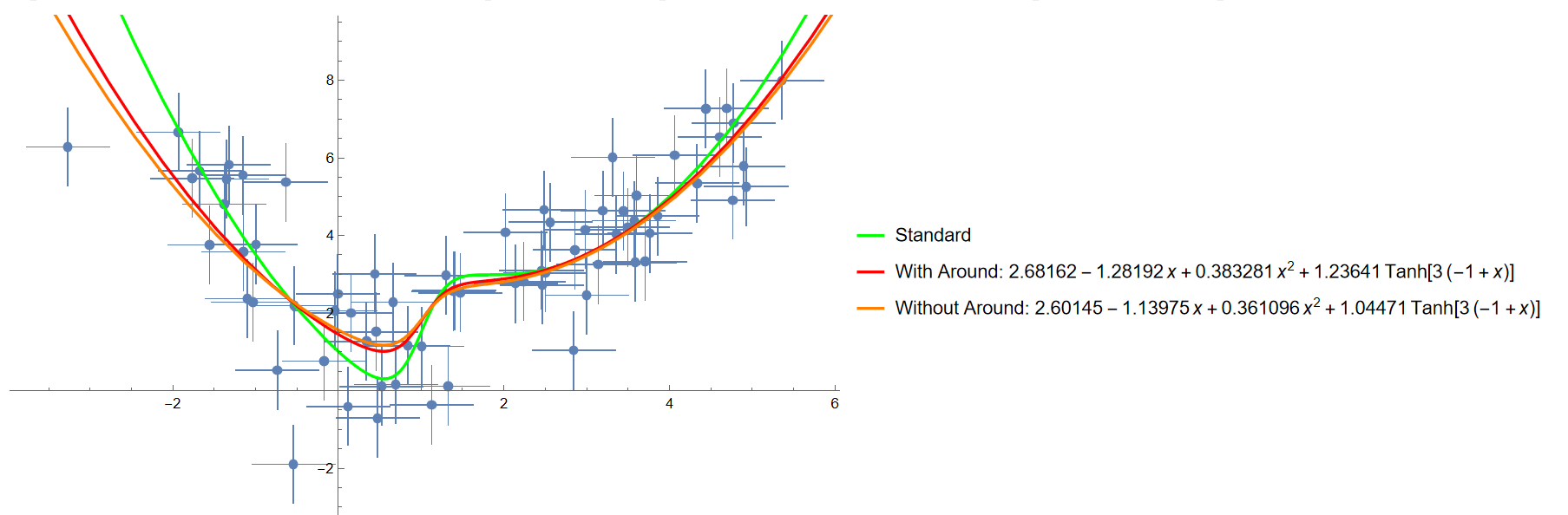
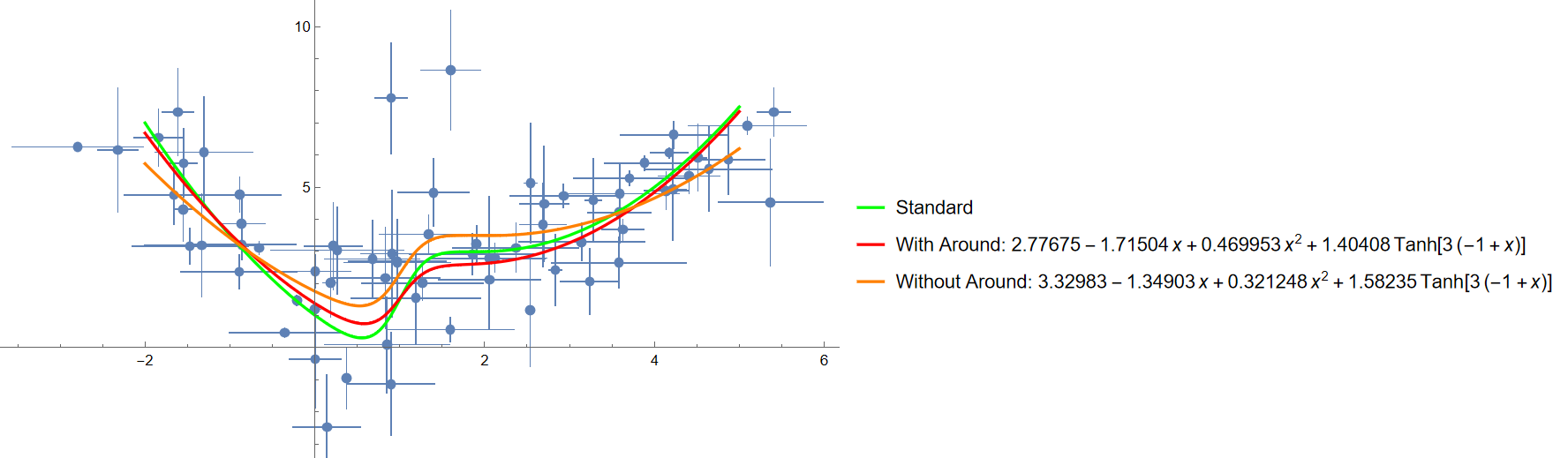
Aluria 于是我就设计了一个简单的函数, 并生成带测量误差的 x,y 值, 测试拟合的效果和区别.
f[x_] := 0.5 x^2 - 2 x + 3 + 2 Tanh[3 (x - 1)];
data0 = Table[{
Around[x + RandomVariate[NormalDistribution[0, 0.5]], 0.5],
Around[f[x] + RandomVariate[NormalDistribution[]], 1]},
{x, -2, 5, 0.1}];
data0e = Map[#["Value"] &, data0, {2}];
data 是一组数据, 调用了 f[x] 函数, 从 -2 到 5 间隔 0.1, x 的误差为 $\sigma = 0.5$ 的正态分布, 而 y 的误差服从 $\sigma = 1$ 的正太分布.
这一组数据的特点是, x,y 都有误差, 但误差是恒定的分布, 每一组数据都是相同的误差.
data0e 是取的 Around[] 数据的['Value'] 属性, 也就是中心值.
我们分布对 data 和 data0e 进行拟合, 可以观察到带误差的数据拟合结果稍好于不带误差的数据, 也就是红色的线距离绿色的线更近
lm0 = LinearModelFit[data0, {x^2, x, Tanh[3 (x - 1)]}, x];
lm0E = LinearModelFit[data0e, {x^2, x, Tanh[3 (x - 1)]}, x];
Show[ListPlot[data0, ImageSize -> Large],
Plot[{f[x], lm0[x], lm0E[x]}, {x, -8, 8},
PlotStyle -> {Green, Red, Orange},
PlotLegends -> {"Standard",
"With Around: " <> ToString[lm0[x], StandardForm],
"Without Around: " <> ToString[lm0E[x], StandardForm]}]]
之前的可以理解为木头尺子+脉搏计时的数据, 消除了一定的漂移带来的影响
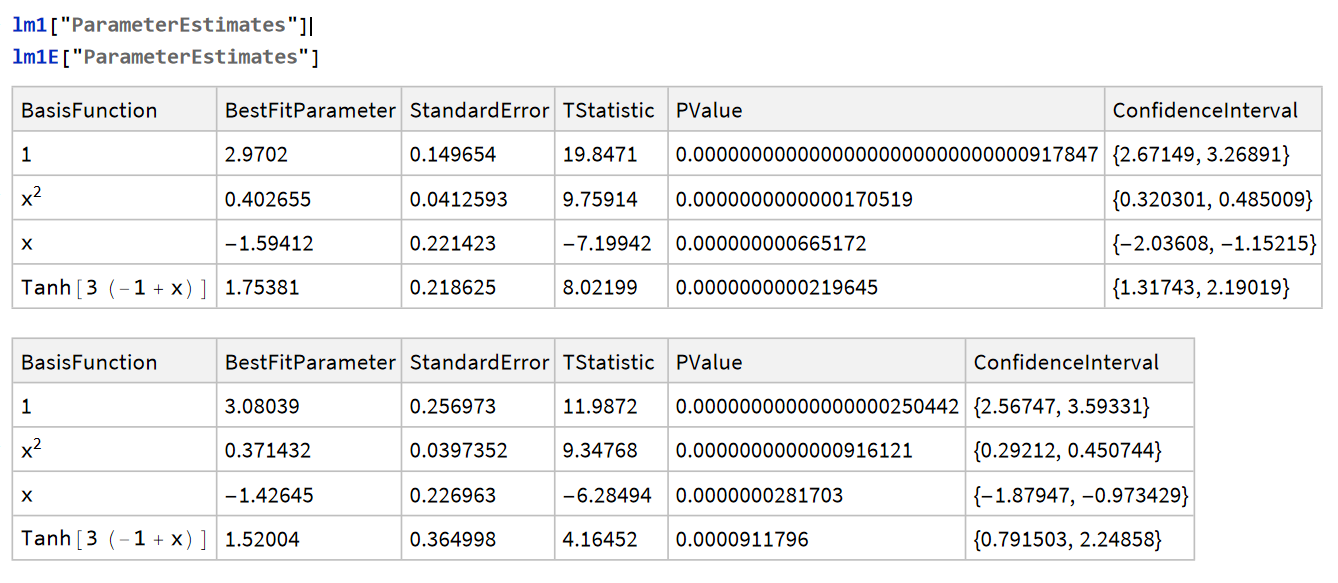
我们再考虑带有变化精度的测量数据, 此时数据的不确定度是会变化但已知的(就像是虽然我用的木头, 但我知道它的不确定的很高, 而且是一个定值可以用尺子的分度值计算出). 此时红色的带误差的线(相当于全面考虑了 x, y 的误差的影响再拟合), 效果就好得多.
data1 = Table[{
Around[x + RandomVariate[NormalDistribution[0, #]], #] &[RandomReal[{0.01, 0.8}]],
Around[f[x] + RandomVariate[NormalDistribution[0, #]], #] &[RandomReal[{0.05, 2.0}]]
}, {x, -2, 5, 0.1}];
data1e = Map[#["Value"] &, data1, {2}];
lm1 = LinearModelFit[data1, {x^2, x, Tanh[3 (x - 1)]}, x];
lm1E = LinearModelFit[data1e, {x^2, x, Tanh[3 (x - 1)]}, x];
Show[ListPlot[data1, ImageSize -> Large],
Plot[{f[x], lm1[x], lm1E[x]}, {x, -2, 5}, PlotStyle -> {Green, Red, Orange},
PlotLegends -> {"Standard", "With Around: " <> ToString[lm1[x], StandardForm],
"Without Around: " <> ToString[lm1E[x], StandardForm]}]]
从另一方面看, 统计量也是带误差的数据更优, 置信区间更小(很反直觉, 但就是事实)
进一步分析可以通过绘制置信区间的图来展示
plotbands[data_, lm_, real_, range_, rangey_] :=
Module[{bands90, bands99, bands9999},
{bands90[x_], bands99[x_], bands9999[x_]} =
Table[lm["MeanPredictionBands", ConfidenceLevel -> cl], {cl, {.9, .99, .9999}}];
Show[
ListPlot[data, ImageSize -> Large, PlotRange -> {range, rangey}],
Plot[{real[x], lm[x], bands90[x], bands99[x], bands9999[x]}, {x, range[[1]], range[[2]]},
PlotStyle -> {Green, Automatic, Automatic, Automatic, Automatic},
Filling -> {3 -> {1}, 4 -> {2}, 5 -> {3}},
PlotLegends -> {"model", "90% confidence bands", "99% confidence bands",
"99.99% confidence bands", "Real Function"}
]
]
]
plotbands[data1, lm1, f, {-3, 6}, {-3, 10}]
plotbands[data1, lm1E, f, {-2, 5}, {-3, 10}]
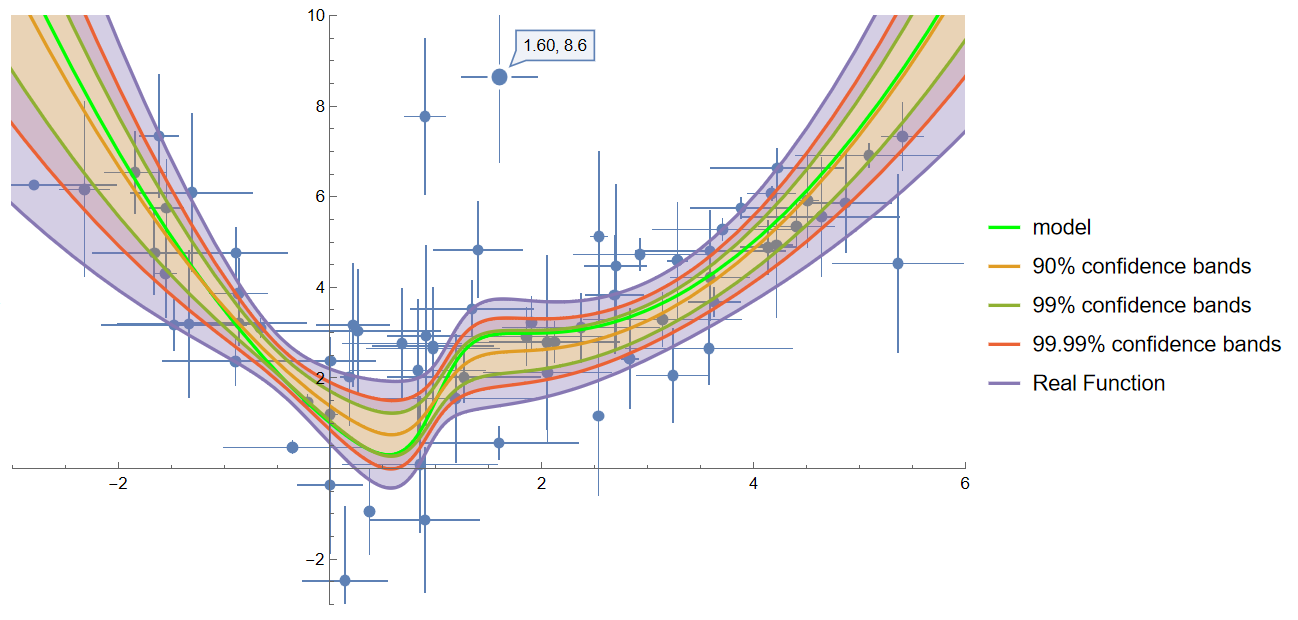
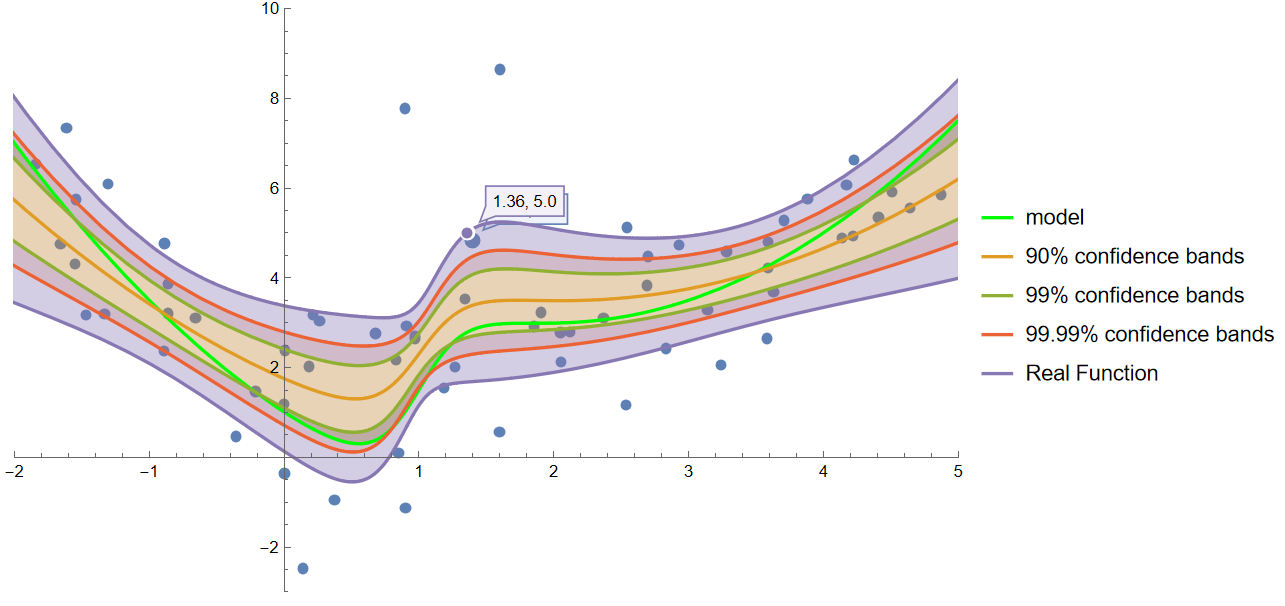
对比上面的两张图, 可以看出, 有些点(1.60, 8.6)虽然偏差很大, 但因为我们知道它的误差大, 因此不必特地迎合这些点, 用置信区间包住它, 所以置信带可以比较窄
而下面的图就不能区分点的偏差, 比如 (1.36, 5.0) 就跟着上面的三个点往上拽, 硬是把一个误差大的点包含在内了.
其实使用 LinearModelFit 是不够严谨的, 它只会把给定的几个表达式乘一个系数, 进行 y 尺度上的缩放, 没有 x 方向上的平移, 对于 x 的误差提现不够显著.
因此如果想进一步验证, 需要使用 NonlinearModelFIt 对参数进行拟合.......
不写啦!
顺便再推一下我写的 MMA Keygen, 我发现可以在别的地方截图再给它加上链接 ( [](link_url) ) 就等效于卡片(乐)